영화 리뷰 데이터 출처: https://grouplens.org/datasets/movielens/
MovieLens
GroupLens Research has collected and made available rating data sets from the MovieLens web site ( The data sets were collected over various periods of time, depending on the size of the set. …
grouplens.org
Table1. Movies
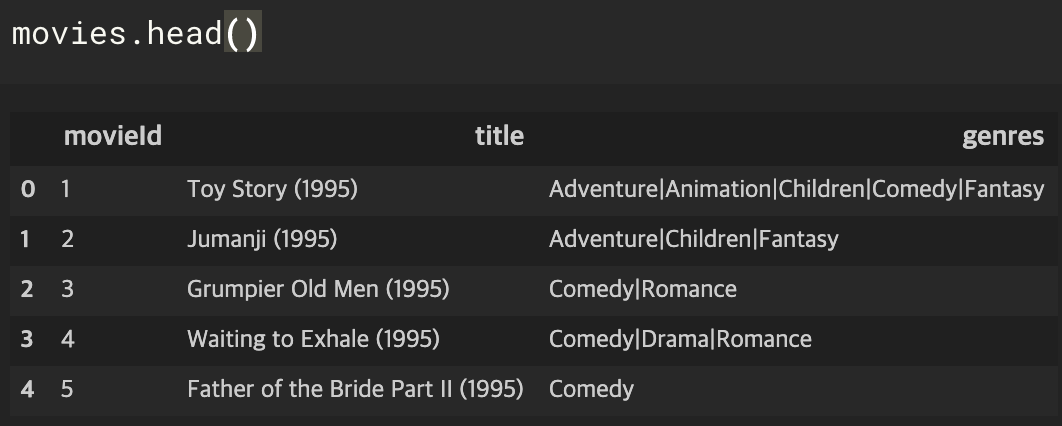
Table2. Ratings

추후 movieId로 두 테이블을 연결할 수 있습니다.
오늘은 ratings 테이블만 사용해서 예측 모델을 만들어보겠습니다.
train, test split
예측모델을 위해, ratings 데이터를 test 10, train 90으로 쪼개주었습니다.

방법1. 전체 별점 평균으로 예측
RMSE = 1.04
train dataset rating 평균 = 3.50

방법2. 유저 별 평균 평점을 기반으로 예측

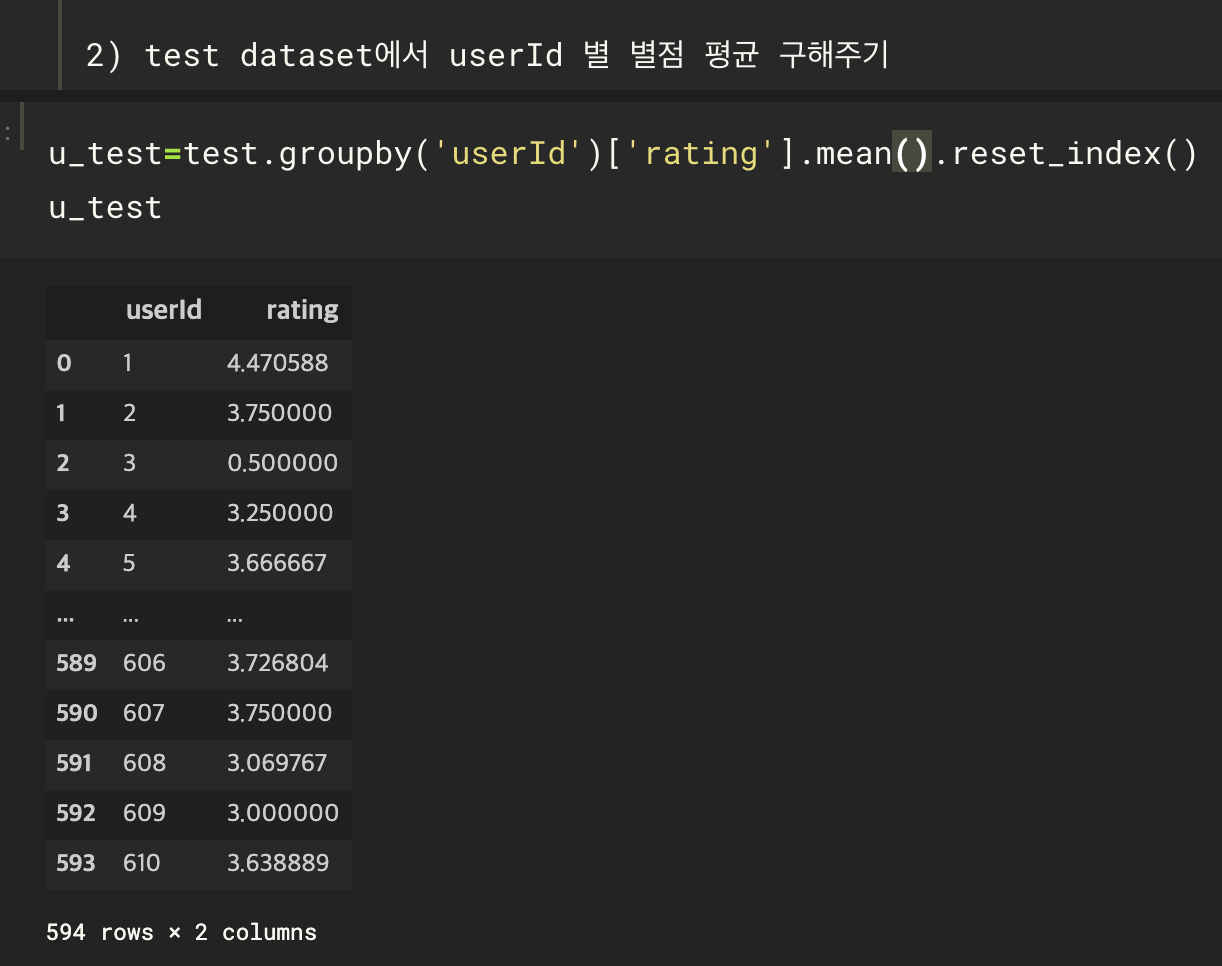

Predict rating에 null 값 없으므로 바로 예측해본다.

방법3. 영화 별 평균 평점으로 예측





정리
모델 별 RMSE 비교
1) 전체 평균: 1.04
2) userid 별 평균: 0.46
3) movieid 별 평균: 0.88
각 모델은 엄청나게 간단하게 만들어져서 각각 한계점을 가지고 있다.
내가 왓챠 같은 영화 별점주는 플랫폼에서 내가 영화마다 어떤 별점을 줄지 서비스에서 예측해준다고 할 때,
1) 전체 평균은 단순히 모든 유저의 모든 영화 별점 평균으로 예측해주는 것이다.
2) userid 별 평균은 내가 평균 4.0점 주는 사람이면 모든 영화에서 나의 선호도와 관계 없이 4.0을 줄것이라고 예측해주는 것이다. 만약에 평균적으로 4.0점을 주지만 너무너무 재미없게 봐서 1점도 주기 아까운 영화에도 4.0점을 줄것이라고 예측하게 된다는 오류가 있다.
3) movieid 별 평균으로 예측한다면, 이것 또한 개인의 선호가 반영되지 않아서 대다수가 주는 별점을 줄것이라고 예측해준다. 만약 내가 대다수의 사람과 다른 선호도를 가진 사람이라면 잘 맞지 않을 것이다.
앞으로 어떻게 더 정교하게 만들지 알아보자!!
* 이 글은 인프런 [개념부터 실습까지] 추천 시스템 입문편 강의를 듣고 작성했습니다.
'Today I Learned > 머신러닝' 카테고리의 다른 글
| K-means Clustering with Python (0) | 2020.11.06 |
|---|---|
| 엑셀로 추천시스템 유저프로필 만들어보기 (0) | 2020.09.30 |
| 모델 평가 지표 - RMSE (0) | 2020.09.29 |
| 내가 쓰는 앱에서 추천시스템 찾아보기 (2) | 2020.09.27 |
| Tensorflow 딥러닝으로 집 값 예측하기 (0) | 2020.09.13 |