반응형
구글스프레드시트 링크에서 실습에 사용한 데이터와, 값을 구할 때 사용한 수식들을 확인하실 수 있습니다.
데이터 셋
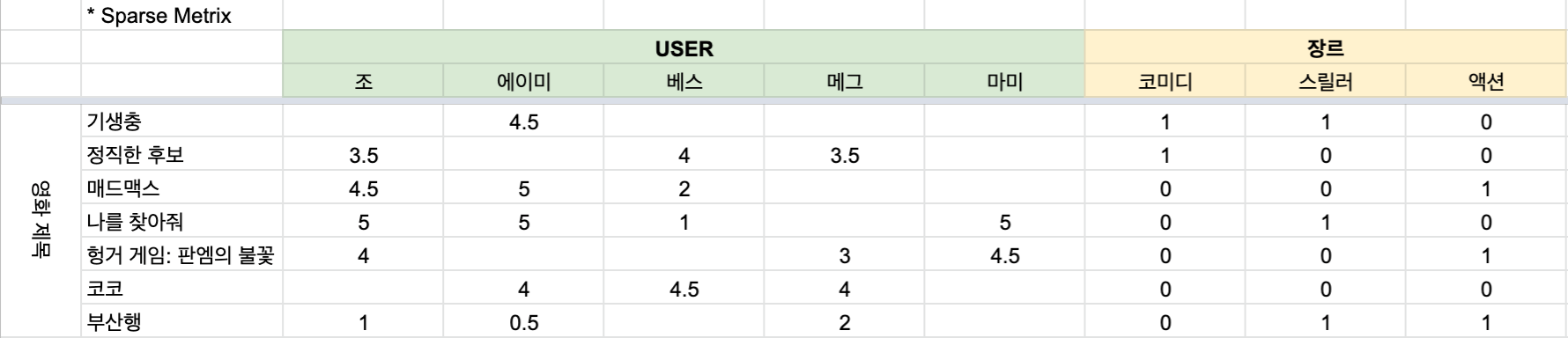
1. User가 준 영화 평점들을 참고하여 각 User들의 장르 별 평균 평점 테이블 만들기
수식 예시)
조 - 코미디: 코미디 장르인 영화에 준 평점 평균 = (기생충 평점 + 정직한 후보 평점) / 2 = ( null + 3.5 ) / 1 = 3.5
-> 평점을 주지 않은 셀은 평균에 참고하지 않는다.

* Cold Start 문제: 초기 데이터가 없어서 추천 해줄 수 없음
마미 - 코미디: 마미가 코미디 장르에 준 평점이 하나도 없어서 평균을 구해주지 못하는 cord start 문제가 발생했다.
이런 문제를 해결하기 위해서 마미의 평점 평균 데이터 혹은, 코미디 장르의 평균 평점 데이터등으로 채워주는 걸 생각해볼 수 있다.
2. User Profile 참고하여, Dense Metrix 만들기 (예상 평점 채우기)
user 별로 장르별 평점을 참고해서, 아직 보지 않은 영화에 몇점을 줄 것인지 예상 평점을 채운다. (노란블럭)
이 때 채울 수 없는 블럭이 2가지가 있다.
수식 예시)
조 - 기생충: 기생충 카테고리 [코미디, 스릴러] * 조의 평점 [3.5,3] / 2
1) 마미 - 정직한 후보: 마미 - 코미디 평점 데이터가 없어서 채울 수 없다.
2) 코코 : 코코의 장르 카테고리 정보가 없어서 채울 수 없다.

다음시간에는 이걸 코드로 직접 짜보자
반응형
'Today I Learned > 머신러닝' 카테고리의 다른 글
| Cross Validation (교차검증) 이란? (0) | 2020.11.12 |
|---|---|
| K-means Clustering with Python (0) | 2020.11.06 |
| 영화 리뷰 평점 예측해보기 (0) | 2020.09.30 |
| 모델 평가 지표 - RMSE (0) | 2020.09.29 |
| 내가 쓰는 앱에서 추천시스템 찾아보기 (2) | 2020.09.27 |