이전에 Orange3로 해보았던 실습을 직접 Code로 작성해보는 과정입니다.
머신러닝 야학을 듣고 이해한 내용을 바탕으로 작성했습니다.
잘못된 부분이 있으면 댓글로 알려주세요.
딥러닝이란?

"인공 신경망에 기반하여 많은 양의 데이터를 학습해 뛰어난 성능을 이끌어내는 연구 분야" 이다.
사람의 뇌처럼 컴퓨터가 학습할 수 있도록 만들려고 하는 개념이다.
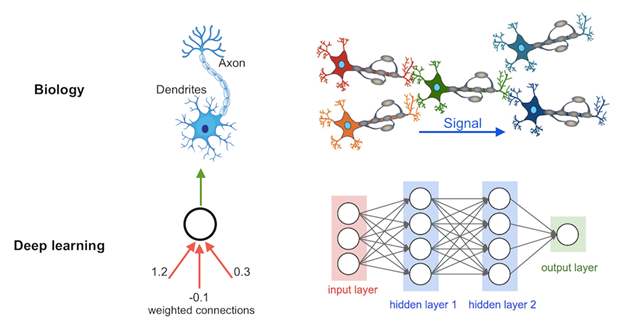
위의 이미지처럼 사람 뇌속의 뉴런이 신호전달을 해서 학습하는 과정에서 착안하여 만들어진것이 딥러닝이다.
Input(X) 와 Output(y) 사이에 Hidden layer를 두고 모델을 학습시켜서 예측 모델을 만드는 것이다.
여기서 Hidden layer 가 포인트이다. 이 부분은 사람이 계산하거나 알아낼 수 없다.
딥러닝은 연산이 매우 복잡한데, 최근 컴퓨터의 성능이 폭발적으로 증가하면서 딥러닝의 성능이 다시 대두되고 있다고 한다.
Tensorflow VS Scikit-learn
이 전에 학습할 때 주로 scikit-learn을 사용했는데, tensorflow와 어떤 차이를 가지고 있는지 궁금해져서 찾아보았습니다.
두가지 모두 간단하게 머신러닝을 구현하게 해주는 라이브러리로, 데이터분석 시 import 함수로 불러와서 사용할 수 있습니다.
참고 자료를 보면 텐서플로우는 로우 레벨 언어로 만들어진 라이브러리이기 때문에 계산 속도가 더 빨라서 딥러닝에 적합하다고 생각할 수 있습니다.
(아직 깊게 다양한 알고리즘을 학습하지 않아서 이정도만 이해하고 넘어가겠습니다.)
| 분류 | 라이브러리 언어 레벨 | 학습 속도 | 강점 | 단점 |
| Tensorflow | low-level | 빠름 | 딥러닝 지원 | 결정트리, 논리 회귀, K-means 등의 머신러닝 알고리즘 지원하지 않음 |
| Scikit-learn | high-level | 비교적 느림 | 지도학습, 비지도학습 관련 다양한 메서드 지원 | 딥러닝 지원하지 않음 |
딥러닝 예측 순서
머신러닝 학습과 순서가 동일합니다.
1. 과거 데이터 준비
2. 독립변수와 종속변수 분류
3. 모델 만들기
4. 데이터로 모델 학습시키기
5. 예측하기 (모델 사용하기)
0. 라이브러리 불러오기
import pandas as pd
import tensorflow as tf
1. 과거 데이터 준비하기
file1 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
boston = pd.read_csv(file1)
print(boston.columns)
boston.head()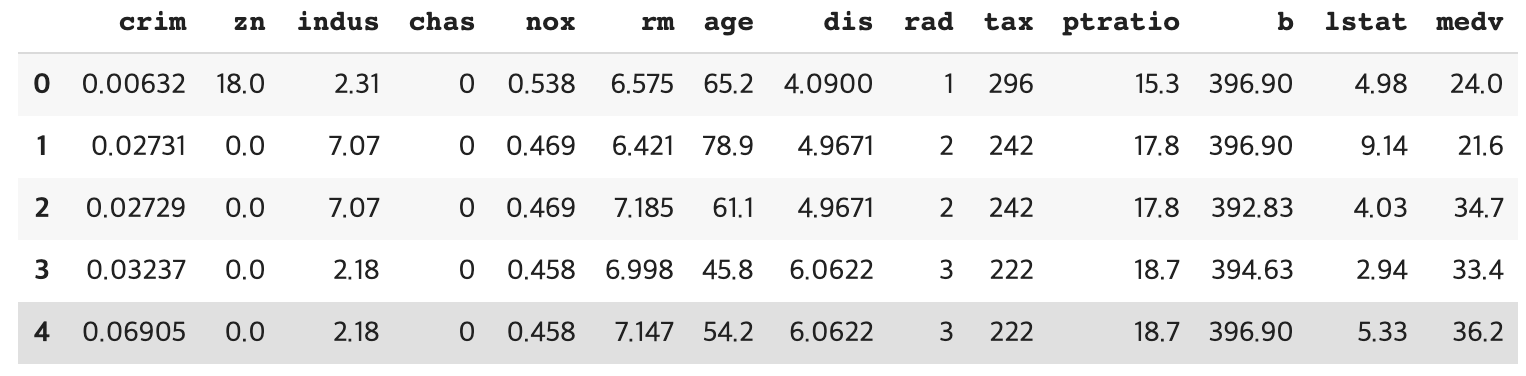
2. 독립변수 (feature), 종속변수 (target)으로 분류하기
feature = boston[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
target = boston[['medv']]
3. 모델만들기
X = tf.keras.layers.Input(shape=[13]) #피쳐의 개수 넣어줌
H = tf.keras.layers.Dense(10, activation='swish')(X)
y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X,y)
model.compile(loss='mse')- shape=[13]: 13은 feature(input)의 갯수
- H: hidden layer를 만드는 부분
- 1) hidden layer node 갯수: dense 뒤에 오는 숫자 -> 현재 코드에서는 10
- 2) hidden layer 갯수: H = tf.keras.layers.Dense(10, activation = 'swish')(X) 이 한줄을 원하는 갯수만큼 작성

*히든레이어 설명 추가
만약 위와 같은 모델을 만든다면, hidden layer는 2개이며, 각각 hidden layer의 node는 4개라고 할 수 있다.
이 때 히든레이어 부분 코드는 다음과 같이 쓸 수 있다.
H = tf.keras.layers.Dense(4, activation='swish')(X)
H1 = tf.keras.layers.Dense(4, activation='swish')(H)
y = tf.keras.layers.Dense(1)(H1)
4. 모델 학습시키기 (fit)
model.fit(feature,target,epochs=1000,verbose=0)- epochs: 학습 시키는 횟수
- verbose=0: 학습 과정 출력 여부 -> 출력시키면 학습 속도 느려짐
이때 재밌었던건 히든레이어가 있고 없고의 차이였다.
히든레이어 없이 학습 시켰을 때는 loss의 최소값이 24 정도에서 머물렀었는데, node 10개인 hidden layer 1개 추가 후 학습시키니 loss가 16까지 떨어지기도 했다.
히든레이어의 중요성.. ⭐️감탄


5. 예측하기
model.predict(feature)앞에 5개 데이터로 비교해보니, 0번,1번 index 에서는 오차가 좀 큰데, 3,4,5번에서는 비슷하게 맞추는걸 확인할 수 있었다.

배운점, 앞으로 학습 계획
알고리즘을 사용할 때 어떻게 튜닝하느냐에 따라서 결과가 달라질 수 있다는 것을 배웠다. 이걸 어떻게 잘 튜닝할 수 있을지 공부해야겠다.
해결하고자 하는 문제를 정의하고 머신러닝, 딥러닝 알고리즘을 적용해서 해결하는 방법으로 학습해보려고 한다.
나만의 머신러닝 만들어보자!
'Today I Learned > 머신러닝' 카테고리의 다른 글
| 영화 리뷰 평점 예측해보기 (0) | 2020.09.30 |
|---|---|
| 모델 평가 지표 - RMSE (0) | 2020.09.29 |
| 내가 쓰는 앱에서 추천시스템 찾아보기 (2) | 2020.09.27 |
| Orange3로 코딩없이 머신러닝 지도학습 실습해보기 (0) | 2020.09.08 |
| 머신러닝 야학 입문 - 머신러닝 분류하기 (0) | 2020.08.31 |