2020/08/31 - 머신러닝 야학 입문 - 머신러닝 분류하기
머신러닝 야학 입문 - 머신러닝 분류하기
이 블로그는 생활코딩 이고잉님의 머신러닝 야학을 듣고 스스로 이해한 내용을 바탕으로 작성합니다. 잘못된 내용이 있으면 댓글로 알려주세요 :) 머신러닝 야학 신청하러 가기 👉🏻 머신러닝
hanawithdata.tistory.com
우선 들어가기전에 K-means cluster는 머신러닝 종류에서 어디에 해당하는지 확인해보자
분류(classification) vs 군집(clustering)의 차이는?
분류와 군집의 차이를 알아야 한다.
분류는 Y(라벨) 이 정해져 있는 지도학습 중 하나이고, 군집은 Y(라벨) 없이 최대한 가까운 데이터끼리 묶어주는 것이다.
K-means cluster는 y 라벨값이 없으며, 독립변수만으로 비슷한 데이터끼리 묶어주는 것이다. (그래서 답이 정해져 있지 않다)
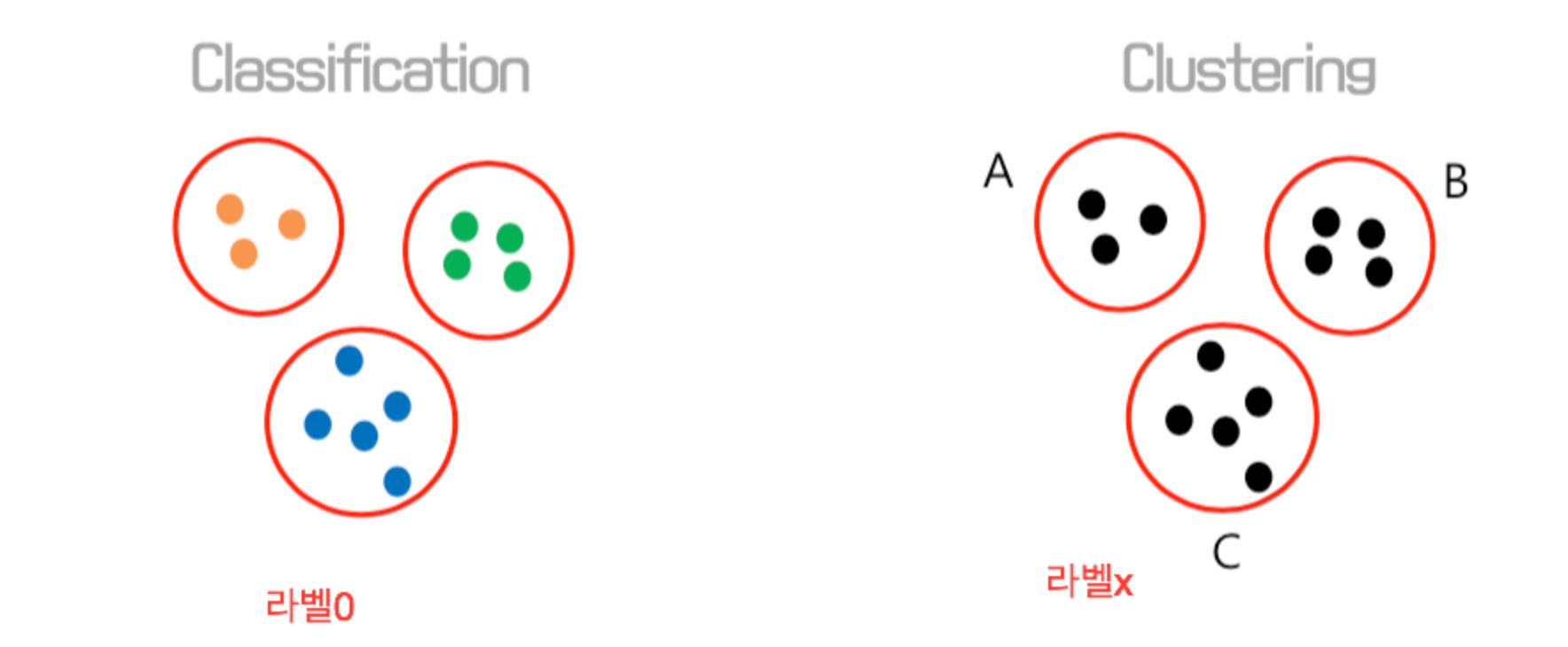
참고 블로그: leonard92.tistory.com/9
[KNN] 1. Classification (분류) vs Clustering (군집화)
[KNN] 1. Classification (분류) vs Clustering (군집화) KNN 에 앞서 이번 시리즈 에서는 KNN 알고리즘에 대해서 설명하려고 합니다. 그런데 KNN 알고리즘을 설명하기 이전에 먼저 알고 가야 할 것이 있는데요,
leonard92.tistory.com
Sklearn Kmeans 알고리즘으로 군집분석하기
plotly는 시각화를 제공하는 도구인데, 머신러닝 분류 데이터로 유명한 iris 데이터를 제공한다.
1) 데이터 준비하기
import plotly.express as px
df = px.data.iris()
2) 독립변수로 scatter plot 그려서 분포 확인해보기
군집화를 하기 전에 눈으로 데이터의 분포를 확인해보자!
fig=px.scatter_3d(
df,
x = 'sepal_length',
y = 'sepal_width',
z = 'petal_width',
color = 'petal_length'
)
fig.show()
3) Clustering
- sklearn 의 Kmeans 모듈을 불러옵니다.
- X 에 군집화에 사용할 독립변수를 넣어줍니다.
- Kmeans 함수에서 n_clusters 파라미터를 나누어줄 군집수를 설정해줍니다.
from sklearn.cluster import KMeans
X = df[['sepal_length','sepal_width','petal_length','petal_width']]
kmeans = KMeans(n_clusters=3, random_state =0).fit(X)4) Cluster 한 결과 살펴보기
* 함수 이름 마지막에 _ 으로 끝나는 것들은 kmeans 실행한 결과값들에 대한 것
4.1 ) kmeans.labels_ : df에서 row마다 어떤 군집으로 분류 되었는지 라벨링 해줍니다.

4.2 ) kmeans.cluster_centers_: 각 군집의 mean 값
- array row -> label (0,1,2)
- array columns -> X (독립변수: 'sepal_length','sepal_width','petal_length','petal_width')

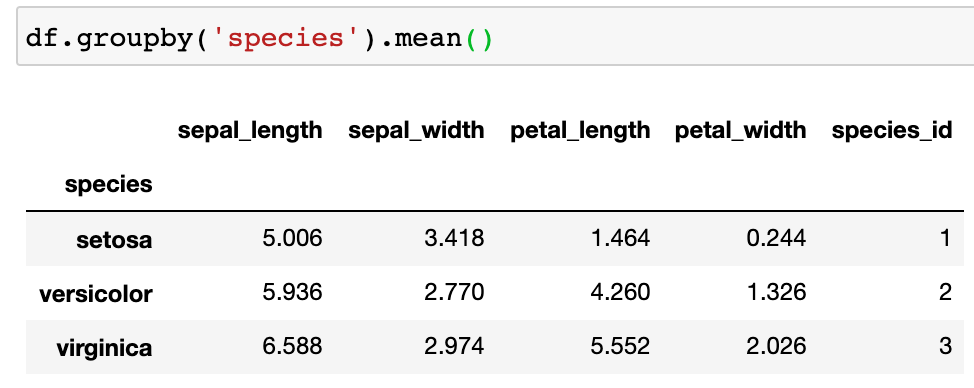
iris 데이터 셋에서 3개의 종으로 분류되어 있는데, group by 해서 mean 값을 보니 kmeans 로 군집화한 군집의 mean 값과 동일했다.
군집화가 제대로 된 것 같다!!
4.3 ) 군집한 결과 시각화
fig = px.scatter_3d(
df, x='sepal_length', y='sepal_width', z='petal_width',
color = kmeans.labels_
)
fig.show()
5) 평가하기
inertia 구하기: 군집 내 평균과의 차이 제곱 합
각 군집에서 평균과의 차이가 작을 수록 좋은 분류이다. 그래서 inertia가 작을수록 잘 분류되었다고 볼 수 있다.
- kmeans.inertia_ : KMeans 모듈에서 제공되는 함수로 구할 수 있다.

하지만 군집 k 수는 커지면 커질수록 평균과의 차이가 작아진다는 점이 있다.
6) K 정하기
- inertia 가 작아지는 기울기가 완만해지는 k 를 지정 (어느정도 적당한 K 고르기)
for 문을 돌면서, K가 2일때부터 11일때까지 Kmeans 군집화에서 inertia를 구해줍니다.
결과를 시각화해서 inertia 의 감소가 완만해지는 부분을 찾습니다.
import matplotlib.pyplot as plt
wcss=[]
for k in range(2,11):
kmeans = KMeans(n_clusters = k, random_state=0).fit(X)
wcss.append(kmeans.inertia_)
plt.plot(ks, wcss)
이미지를 보고 K의 수를 3 또는 4로 하면 되겠다! 라고 판단합니다.
'Today I Learned > 머신러닝' 카테고리의 다른 글
| [자연어처리] konlpy 설치하고 불러오기 (0) | 2020.11.20 |
|---|---|
| Cross Validation (교차검증) 이란? (0) | 2020.11.12 |
| 엑셀로 추천시스템 유저프로필 만들어보기 (0) | 2020.09.30 |
| 영화 리뷰 평점 예측해보기 (0) | 2020.09.30 |
| 모델 평가 지표 - RMSE (0) | 2020.09.29 |