반응형
1. 라이브러리 Import
여기서 회귀분석을 도와주는 라이브러리는 맨 위에 ols 이다!
from statsmodels.formula.api import ols
import pandas as pd
import matplotlib.pyplot as plt2. 회귀분석 할 파일 불러오기
speed에따른 제동거리를 선형회귀분석 해보자
- 독립변수: speed
- 종속변수: dist
df = pd.read_excel('data/speed.xlsx')
df.head()
3. Scatter plot으로 분산 그려보기
df.plot.scatter('speed','dist')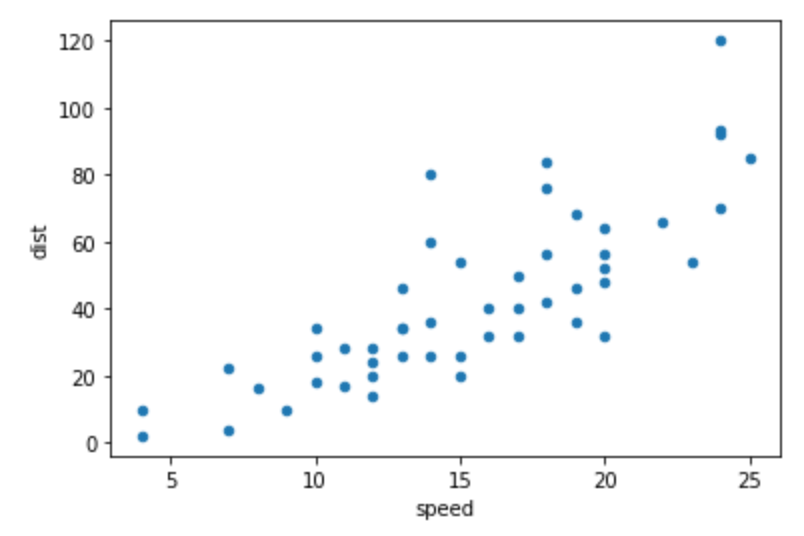
4. ols('y ~ x' ,data).fit() 모형 적합시키기
'y ~ x1 + x2 + x3' -> 독립변수가 여러개 일 경우에는 + 로 추가해줍니다.
res=ols('dist ~ speed',data=df).fit()5. 결과지 확인하기
res.summary()
1) 계수
- 절편(Intercept): -17.5791
- speed의 기울기: 3.9324
- 모형 수식: y = 3.9324 * X - 17.5791
-> speed 1 증가할 때, 제동거리는 3.9 증가합니다.
2) 신뢰구간
신뢰구간은 P-value와 같이 본다.
P-value < 유의수준일 경우 계수의 신뢰구간이 + 또는 - 에서만 존재한다.
만약 신뢰구간이 -1 ~ 1 이라면 통계적으로 유의하다고 보기 어렵다.
speed는 표준오차(std) 0.416으로 95% 신뢰구간으로 보면 [0.025] ~ [0.975] 에서 모두 양수,
P-value < 유의수준이 0.05보다 작으므로 통계적으로 유의하다고 해석한다.
3) 모형 적합도 지수
R-squared, adj.R-squared, AIC, BIC 등이 있다. 여러 모형 중에 적합도 지수가 좋은 모형을 선택한다!!
- R-squared = 1 - Rss / Tss
- RSS: 회귀분석 이후 남은 잔차 제곱 합
- TSS: 회귀분석 이전 남은 잔차 제곱 합
회귀분석 이후 잔차가 많이 줄어들수록 R제곱 커진다. 따라서 R제곱이 클수록 설명력이 높다고 할 수 있다!
R제곱이 0.651로 65%의 설명력을 가진다고 할 수 있다.
- adjusted R-squared = 1 - (RSS /(n-k-1)) / (TSS/(n-1))
- n: 표본의 크기
- k: 독립변수의 개수
R제곱은 독립변수를 추가할때마다 커지게 된다. 따라서 불필요한 독립변수를 추가하면 작아지도록 보정해준게 수정 R 제곱이다!!
그래서 모형을 고를때 수정 R 제곱을 봐주는것이 좋다.
반응형
'Today I Learned > 통계' 카테고리의 다른 글
| 회귀분석(1) - RSS가 최소가 되도록하는 OLS (0) | 2020.10.09 |
|---|---|
| 통계적 가설 검정 - 1종 오류가 더 위험한 이유 (1) | 2020.09.25 |
| P-value 로 두 집단에 차이가 있는지 검증하기 (0) | 2020.09.22 |
| Excel 로 표본 데이터의 신뢰 구간 구하기 (0) | 2020.09.01 |
| 행복 몰빵 vs 잔잔바리 행복 (0) | 2020.08.31 |