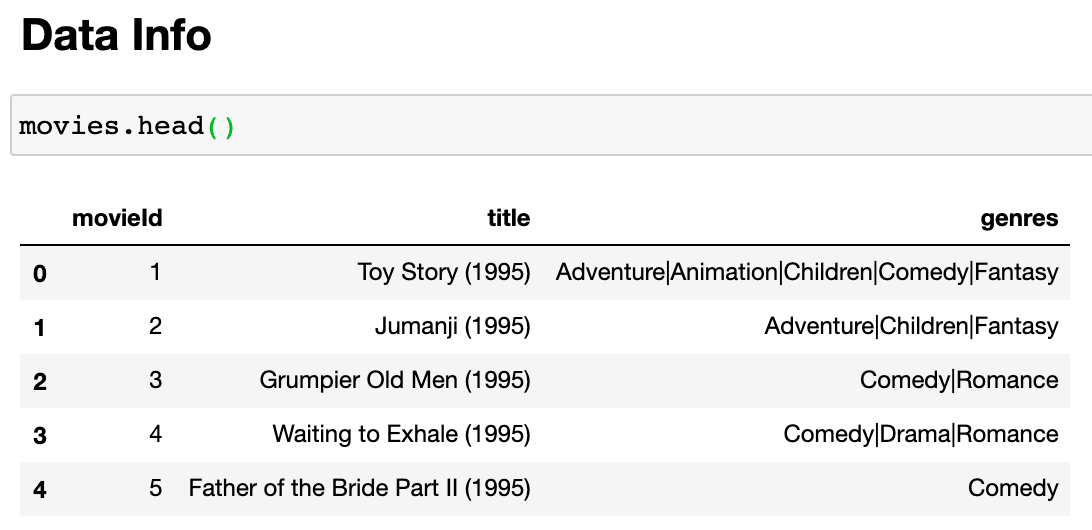
전처리 과정중 하나로 컬럼 값이 categorical 타입일 때, 추후 편리한 연산을 위해 True or False (1 or 0) 값으로 변경해주는 것이 좋다. 하나의 컬럼안에 여러 중복 값이 있을 때 이를 유니크한 단위로 쪼개서 정리해줄 수 있는데, 아래 예시를 살펴보자 영화 데이터인데, 'genres' 컬럼을 보면, 한 컬럼안에 복수개의 장르가 들어가있는걸 볼 수 있다. 이런 데이터는 다루기 까다로우니, 전처리가 필요하다. 방법1. for 문 활용 1) unique genres 추출 2) genres unique list 활용해서 For 문으로, 각 row의 genres column에 해당 장르가 포함 되어있으면, True, 없으면 False 할당해서 새로운 컬럼 생성해줌 방법2. get_dummi..