2020 런닝맨 시청율 정보를 크롤링 해와서 시각화 해보기를 해보겠습니다.
런닝맨/2019년 - 나무위키
회차방영일닐슨TNMS433회01.067.3%8.2%434회01.136.4%7.2%435회01.207.3%6.9%436회01.276.0%7.6%437회02.036.2%7.1%438회02.107.8%8.0%439회02.176.7%7.9%440회02.246.5%7.1%441회03.036.5%6.4%442회03.106.7%6.9%443회03.177.5%7.4%444회03.246.7%7.2%445
namu.wiki
필요한 라이브러리 Import
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs결과물 형태
크롤링한 정보를 아래와 같은 테이블로 만들어주겠습니다.

페이지 정보 요청하기
requests.get() 으로 요청해서 정보 받아오고, beautifulsoup으로 깔끔하게 정리해준다.
url = 'https://namu.wiki/w/%EB%9F%B0%EB%8B%9D%EB%A7%A8/2019%EB%85%84'
res = requests.get(url)
soup = bs(res.content,'html.parser')원하는 정보 추출하기
콘텐츠 구조가 아래 두 태그가 반복되는 형태
- h2 class='wiki-heading'
- div class='wiki-heading-content'
-> 따라서 3. 시청률 추이 콘텐츠는 3번째 반복될 때 나오고 인덱스로 2

data=soup.select('.wiki-heading-content')[2]
해당 div 안에 시청률 데이터가 table 형태로 제공되고 tr > td 안에 한줄로 데이터가 들어있음
table=data.find('table',{'class':'wiki-table'}).find_all('td')회차, 방영일, 닐슨, TNMS 정보를 리스트에 넣어주기
table 출력해보면, td태그로 한줄씩 정보를 가지고 있고, 각 값이 회차인지, 방영일인지, 닐슨인지 , TNMS인지 구분해주는 속성값을 가지고 있지 않다.

4씩 증가하면서 같은 컬럼 정보가 반복되기 때문에 For 문을 사용해서 list에 추가해주는 방식을 사용한다.
# 빈 리스트 만들기
회차 = []
방영일 = []
닐슨 = []
TNMS = []
# 리스트에 값 넣어주는 함수 만들기
def make_list(n,list_name):
for t in range(n,len(table),4):
list_name.append(table[t].text)
# 리스트에 값 넣어주기
make_list(4,회차)
make_list(5,방영일)
make_list(6,닐슨)
make_list(7,TNMS)데이터프레임으로 만들기
df=pd.DataFrame({'회차':회차,
'방영일':방영일,
'닐슨':닐슨,
'TNMS':TNMS})
Plotly 시각화
Getting Started with Plotly
Getting Started with Plotly for Python.
plotly.com
import plotly.express as px
import plotly.graph_objects as goLine Chart
fig=px.line(df, x='방영일', y=['닐슨','TNMS'] ,title = '런닝맨 시청률(닐슨)')
fig.show()
12월 8일 TNMS 시청율에 특이 값이 있는데, 8.4%를 8,4% 로 오타 냈음
# 오타 수정
df.loc[df['방영일'] =='12.08','TNMS'] = '8.5%'> 오타 수정해준다.
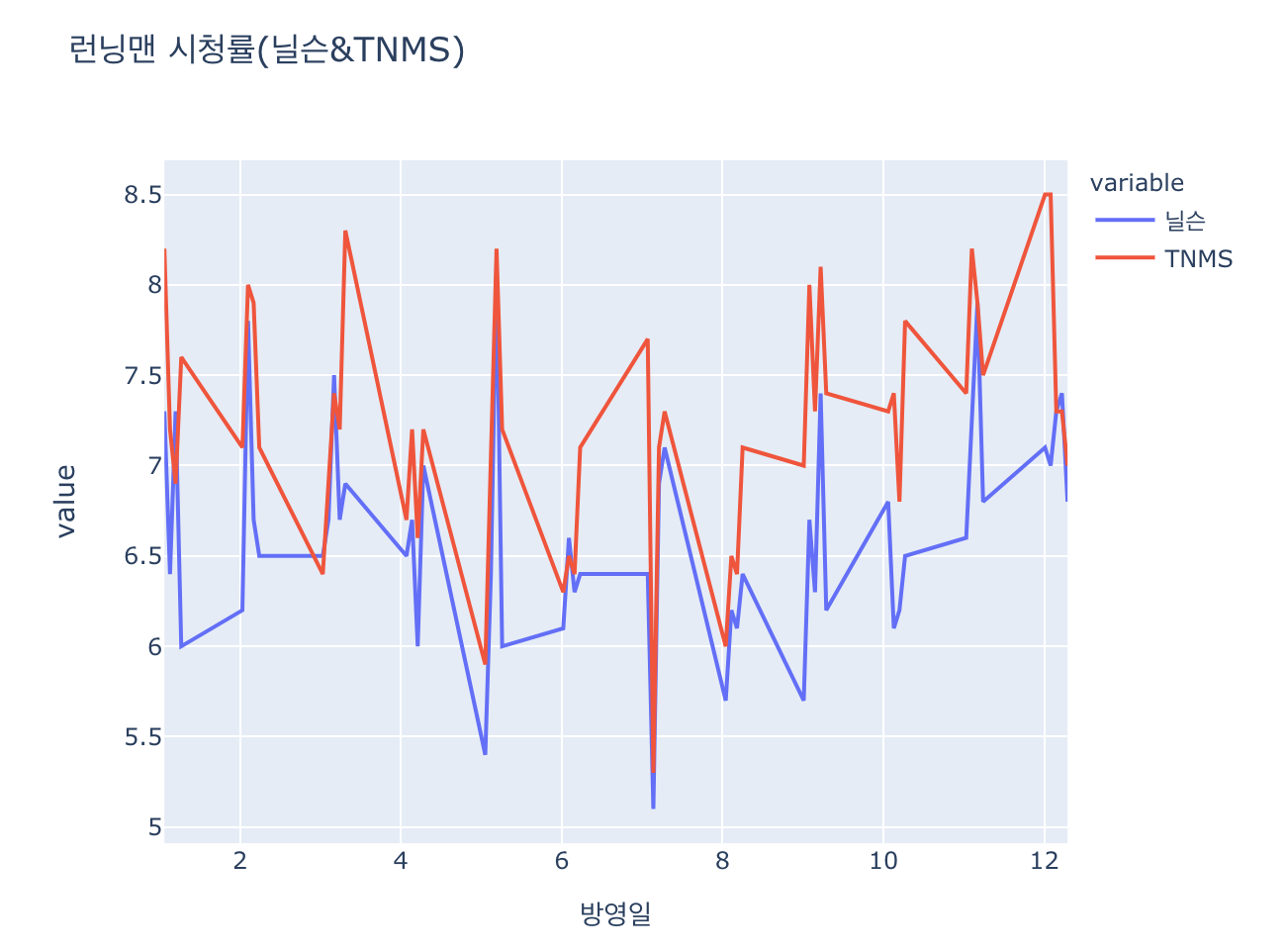
Lines + Markers Chart
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['방영일'],y=df['닐슨'],mode='lines+markers',name='닐슨'))
fig.add_trace(go.Scatter(x=df['방영일'],y=df['TNMS'],mode='lines+markers',name='TNMS'))
fig.update_layout(title ='2020 런닝맨 시청율 (닐슨 & TNMS)')
fig.write_html('first_figure.html', auto_open=True)
fig.show()
크롤링으로 읽어온 데이터를 데이터프레임으로 만들고, 그 데이터를 plotly 라이브러리를 활용해서 시각화하는 것 까지 해보았습니다.
시각화를 통해서 오타까지 발견!! 시각화는 빠르게 전체 데이터 분포를 확인하는데 좋은 도구라는 점을 한번더 배웠습니다.
'Today I Learned > Python & Pandas' 카테고리의 다른 글
| 파이썬(Python) array, list, tuple, set 함수 및 특징 정리 (0) | 2023.06.08 |
|---|---|
| [Python] 네이버 데이터랩 크롤링 (BeautifulSoup & Selenium) (1) | 2020.11.04 |
| [Python] Unittest 모듈로 단위테스트해보기 (0) | 2020.10.26 |
| [Python] News Crawling (0) | 2020.10.20 |
| [Python] datetime, timedelta 라이브러리 사용해서 Timetable 만들기 (0) | 2020.10.14 |